1.4. Quantile regression and expectile regression#
1.4.1. Introduction: quantile regression#
Suppose, from some unknown distribution of \((y, X)\), we draw a random sample \(\{(x_1, y_1), (x_2, y_2), \ldots, (x_n, y_n)\}\), where \(x_i\) is a \(p\)-dimensional covariates/features/predictors and \(y_i\) is an interesting response. We stack these sample into: \(y \in R^n\) and \(X \in R^{n\times p}\). We assume the conditional quantile of \(y\) given \(X\) (denoted as \(Q_{\tau}(y|X)\)) is the following linear model:
where \(\beta^{*}_{\tau}\) is the regression coefficient vector for modeling \(Q_{\tau}(y|X)\).
Why quantile regression is helpful? Here are the advantages in Wiki [1].
Quantile regression enables the understand of the impact of covariates on more generally the tails of the distribution of the response. This supports more comprehensively analyse for the relationship between variables. For example, a application of quantile regression is in the areas of growth charts, where percentile curves are commonly used to screen for abnormal growth.
The quantile regression estimates are more robust against outliers in the response measurements.
But, in reality, \(\beta^{*}_{\tau}\) is unknown and has to be estimated by data \(\{(x_1, y_1), \ldots, (x_n, y_n)\}\). The estimation approach is minimizing the loss function:
where \(r_{\tau}(m) = m (\tau - I(m<0))\) and \(I(\cdot)\) is the indicator function.
1.4.2. Sparse quantile linear model#
Nowadays, the number of predictor may be hundreds or even thousands. To gain a more interpretable model, a natural idea is encouraging sparsity when minimizing the loss function [2], [3]. With skscope, we can easily solve the following sparsity-constrain quantile regression:
Here, we restrict the number of non-zero entries in \(\beta\) (i.e., \(\|\beta\|_0\)) is smaller than \(s\).
We now use the skscope to solve this problem. To exemplify our implementation, we first generate synthetic datasets via the following model:
where \(\epsilon\) comes from the standard normal distribution \(N(0, 1)\), and the first element of \(x_i\) is the intercept term (takes value 1) and the rest elements are \(i.i.d.\) drawn from the \(N(0, 1)\). We set \(\beta^{*} = (9, 7, 5, 3, 0, 0, \ldots, 0)\). Under this model, we have
Below is the code for synthesizing data.
[1]:
import numpy as np
n, p = 2000, 100
np.random.seed(1)
X = np.random.normal(0, 1, (n, p))
print(X.shape)
X[:, 0] = X[:, 0] / X[:, 0]
beta = np.zeros(p)
beta[:4] = [9, 7, 5, 3]
effect_vars = np.flatnonzero(beta)
y = X @ beta + np.random.normal(0, 1, n)
(2000, 100)
Next, we use the ScopeSolver to estimate the underlying \(\beta^*_{0.975}\).
[2]:
import jax.numpy as jnp
from skscope import ScopeSolver
QUANTILE = 0.975
def quanreg_loss(params):
diff = y - X @ params
weight = jnp.where(diff < 0, QUANTILE - 1, QUANTILE)
loss = jnp.mean(weight * diff)
return loss
solver = ScopeSolver(p, sparsity=4, preselect=1)
params_upper = solver.solve(quanreg_loss)
print("Selected variables: {}, \nestimated coefficients: {}".format(
solver.get_support(),
params_upper[solver.get_support()]),
)
/Users/zhujin/miniforge3/envs/convex-solver/lib/python3.9/site-packages/jax/_src/lib/__init__.py:33: UserWarning: JAX on Mac ARM machines is experimental and minimally tested. Please see https://github.com/google/jax/issues/5501 in the event of problems.
warnings.warn("JAX on Mac ARM machines is experimental and minimally tested. "
Selected variables: [0 1 2 3],
estimated coefficients: [10.95208428 7.02401769 5.04306109 3.00177924]
We can see that the solver correctly select the effective variables. The estimated non-zero coefficients is very closed to the ground truth \((10.96, 7, 5, 3)^\top\).
Next, we plot the estimated quantile regression model.
[3]:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize = (9, 9))
b_upper, a_upper = np.polyfit(X @ beta, X @ params_upper, deg=1)
ax.scatter(X @ beta, y)
ax.plot(X @ beta, a_upper + b_upper * (X @ beta), color="k", lw=1.5, label='quantile=0.99')
ax.legend()
[3]:
<matplotlib.legend.Legend at 0x15f8a7c40>
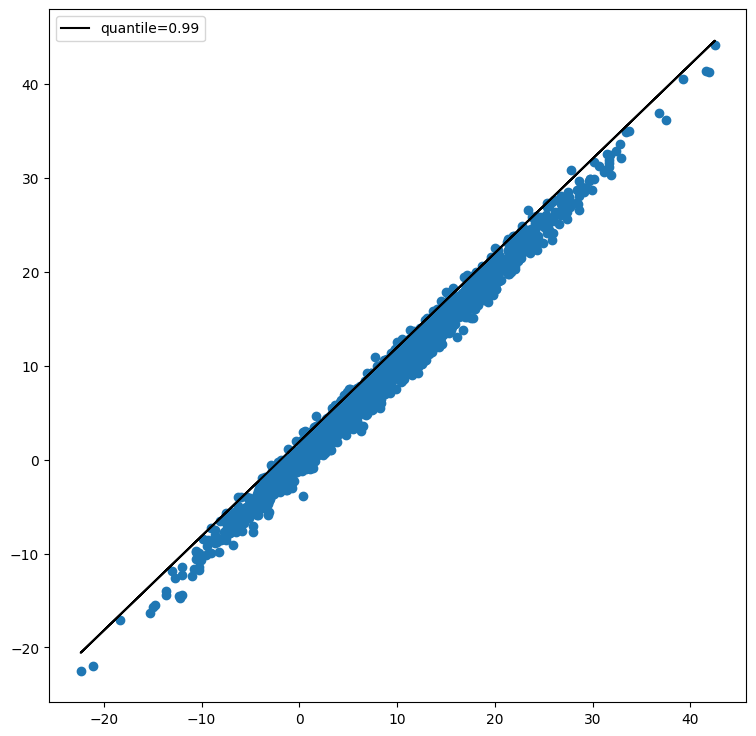
From the above figure, we see that estimated model upperly bound the observations.
Similarly, we can estimate the models when \(\tau = 0.5\) and \(\tau = 0.025\). The implementation based on the scope is given below.
[4]:
QUANTILE = 0.5
solver = ScopeSolver(p, sparsity=4, preselect=1)
params_ols = solver.solve(quanreg_loss)
print("Selected variables: {}, \nestimated coefficients: {}".format(
solver.get_support(),
params_ols[solver.get_support()]),
)
QUANTILE = 0.025
solver = ScopeSolver(p, sparsity=4, preselect=1)
params_lower = solver.solve(quanreg_loss)
print("Selected variables: {}, \nestimated coefficients: {}".format(
solver.get_support(),
params_lower[solver.get_support()]),
)
Selected variables: [0 1 2 3],
estimated coefficients: [8.97916353 6.99756945 4.99368271 2.98584495]
Selected variables: [0 1 2 3],
estimated coefficients: [6.94788394 7.07152796 5.02274821 3.01699366]
Again, the effective variables are perfectly selected; additionally, the estimated coefficient vectors are closed to the \((9, 7, 5, 3)^\top\) and \((7.04, 7, 5, 3)\), respectively. Then, we visualize the above three models:
[5]:
b_upper, a_upper = np.polyfit(X @ beta, X @ params_upper, deg=1)
b_ols, a_ols = np.polyfit(X @ beta, X @ params_ols, deg=1)
b_lower, a_lower = np.polyfit(X @ beta, X @ params_lower, deg=1)
fig, ax = plt.subplots(figsize = (9, 9))
ax.scatter(X @ beta, y)
ax.plot(X @ beta, a_upper + b_upper * (X @ beta), color="k", lw=1.5, label='quantile=0.975')
ax.plot(X @ beta, a_ols + b_ols * (X @ beta), color="g", lw=1.5, label='quantile=0.5 (MAE)')
ax.plot(X @ beta, a_lower + b_lower * (X @ beta), color="m", lw=1.5, label='quantile=0.025')
ax.set_ylabel("y")
ax.set_xlabel("x @ beta")
ax.legend()
[5]:
<matplotlib.legend.Legend at 0x106d5f850>

We can see that the three models properly capture \(Q_{\tau}(y|x)\).
1.4.3. Sparse expectile regression#
Expectile regression is an alternative possibility for characterizing the conditional distribution. It is first proposed in 1970s, and nowadays, it gains increasing interest such as reinforcement learning [4]. For expectile regression, the loss function is replaced with:
which is very similar to that in quantile regression. Notably, expectiles regression contain the ordinary linear regression as a special case (with \(\tau=0.5\)). To see this, we visualize the curve of function: \((r_{\tau}(u))^2\).
[6]:
def square_r_fun(u):
tau = 0.5
weight = np.where(u < 0, 1 - tau, tau)
return weight * (u**2)
x = np.arange(-1.0, 1.01, step=0.1)
fig, ax = plt.subplots(figsize = (3, 3))
ax.plot(x, square_r_fun(x))
[6]:
[<matplotlib.lines.Line2D at 0x15fa92f40>]

Similarly, we can conduct variable selection for expectile regression, which is formulated as a sparsity-constrained optimization:
where the objective function is implemented as:
[7]:
EXPECTILE = np.nan
def asym_loss(params):
diff = y - X @ params
weight = jnp.where(diff < 0, 1 - EXPECTILE, EXPECTILE)
loss = jnp.mean(weight * (diff**2))
return loss
We optimize the objective with the previous synthetic dataset at expectile 0.025, 0.5 and 0.975.
[8]:
EXPECTILE = 0.975
solver = ScopeSolver(p, sparsity=4, preselect=1)
params_upper = solver.solve(asym_loss)
print("Selected variables: {}, \nestimated coefficients: {}".format(
solver.get_support(),
params_upper[solver.get_support()]),
)
EXPECTILE = 0.5
solver = ScopeSolver(p, sparsity=4, preselect=1)
params_ols = solver.solve(asym_loss)
print("Selected variables: {}, \nestimated coefficients: {}".format(
solver.get_support(),
params_ols[solver.get_support()]),
)
EXPECTILE = 0.025
solver = ScopeSolver(p, sparsity=4, preselect=1)
params_lower = solver.solve(asym_loss)
print("Selected variables: {}, \nestimated coefficients: {}".format(
solver.get_support(),
params_lower[solver.get_support()]),
)
Selected variables: [0 1 2 3],
estimated coefficients: [10.40983627 7.01664256 5.02507904 3.0124289 ]
Selected variables: [0 1 2 3],
estimated coefficients: [8.99668813 6.99586902 5.0008044 2.98165417]
Selected variables: [0 1 2 3],
estimated coefficients: [7.54970328 7.02671685 5.03644048 2.95786884]
Again, we see that the effective variables are correctly selected. And we visualize the three estimated models below.
[9]:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize = (6, 6))
b_upper, a_upper = np.polyfit(X @ beta, X @ params_upper, deg=1)
b_ols, a_ols = np.polyfit(X @ beta, X @ params_ols, deg=1)
b_lower, a_lower = np.polyfit(X @ beta, X @ params_lower, deg=1)
ax.scatter(X @ beta, y)
ax.plot(X @ beta, a_upper + b_upper * (X @ beta), color="k", lw=1.5, label='expectile=0.99')
ax.plot(X @ beta, a_ols + b_ols * (X @ beta), color="g", lw=1.5, label='expectile=0.5 (MSE)')
ax.plot(X @ beta, a_lower + b_lower * (X @ beta), color="m", lw=1.5, label='expectile=0.01')
ax.legend()
[9]:
<matplotlib.legend.Legend at 0x15fae7790>
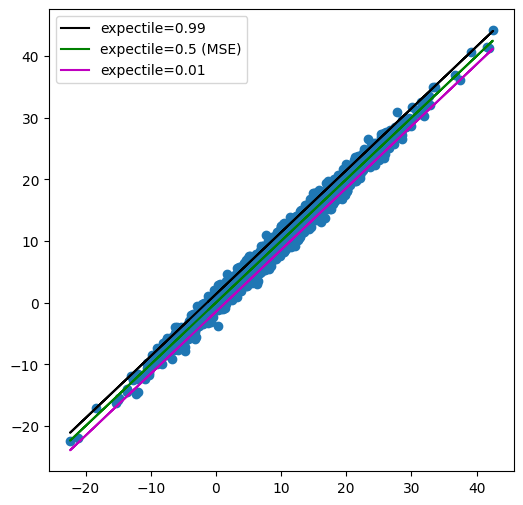
We can notice that the three models also provide a reasonable estimation for conditional expectile and conditional mean.
1.4.3.1. Comparison between expectile regression and quantile regression#
Quantile regression is more resistant to outliers than expectile regression because quantile regression use \(\ell_1\) norm that is more robust against outliers.
In the field of risk measures for financial assets, the use of expectiles as a risk measure as they have desirable properties.
1.4.4. Reference#
[1] Quantile regression. https://en.wikipedia.org/wiki/Quantile_regression
[2] Alexandre Belloni. Victor Chernozhukov. “\(\ell_1\)-penalized quantile regression in high-dimensional sparse models.” Ann. Statist. 39 (1) 82 - 130, February 2011. https://doi.org/10.1214/10-AOS827
[3] Wu, Yichao, and Yufeng Liu. “Variable selection in quantile regression.” Statistica Sinica (2009): 801-817.
[4] Ilya Kostrikov and Ashvin Nair and Sergey Levine. Offline Reinforcement Learning with Implicit Q-Learning. International Conference on Learning Representations (2022)