5.2. Sparse Precision Matrix#
5.2.1. Introduction#
In the field of data analysis and machine learning, estimating the precision matrix has always been an important problem. Traditional optimization problems based on Gaussian graphical models often use the loss function \(L^{\text{GGM}}(\Omega)=\text{tr}(S\Omega)-\log\det \Omega\) for solving. However, this optimization problem is not strongly convex and smooth, and may require additional steps and conditions to achieve the best results. Moreover, this method is essentially applicable only to multivariate Gaussian random vectors.
However, in practical applications, the sample data often does not completely conform to the assumption of multivariate Gaussian distribution. Here are some more specific examples.
Social Network Analysis: Social networks, where nodes represent individuals and edges depict their social connections, often exhibit complex non-Gaussian distributions, such as power-law distributions.
Financial Market Networks: Financial market networks, with nodes representing different assets and edges denoting their interactions, typically demonstrate nonlinearity and non-Gaussian characteristics.
Large-scale Recommendation Systems: Graph-based recommendation systems, capturing user-item interactions, often involve complex distributions that deviate from multivariate Gaussian assumptions. These distributions can include long-tailed distributions, indicating that some items have significantly higher frequencies than others in user behavior data.
In such cases, we would like to obtain a more general loss function for estimating the precision matrix. Since Since \(\Sigma^*\Omega^*=1\), where \(\Sigma^*\) and \(\Omega^*\) are the true values of the covariance matrix and precision matrix respectively, we can consider the discrepancy between \(\Sigma\Omega\) and the identity matrix \(I_{p\times p}\) in some sense, similar to [1], where \(\Sigma\) is the sample covariance matrix.
Here, we consider to minimize another loss function for learning sparse precision matrix, i.e.,
where \(\| \Omega \|_0\) is the number of non-zero entries on upper-diagonal matrix of \(\Omega\) and \(\mathcal{S}^{++}\) is the space of symmetric positive definite matrix.
5.2.2. Examples#
[1]:
from skscope import ScopeSolver
import jax.numpy as jnp
import numpy as np
from sklearn.datasets import make_sparse_spd_matrix
import cvxpy as cp
import matplotlib.pyplot as plt
import seaborn as sns
import scipy.linalg as la
First, we define the loss function \(L(\Omega)\) mentioned above. In this function, since the parameters accepted by scope need to be in vector form, we input a vector composed of the upper triangular part of matrix \(\Omega\) and then restore it to a matrix within the function. Furthermore, we use the cvxpy package to define a solver with symmetric positive definite conditions.
[2]:
def graphical_loss(params, sample_covariance_matrix):
p = sample_covariance_matrix.shape[0]
Omega = jnp.zeros((p, p))
Omega = Omega.at[np.triu_indices(p)].set(params)
Omega = jnp.where(Omega, Omega, Omega.T)
return jnp.linalg.norm(jnp.matmul(sample_covariance_matrix, Omega) - np.diag(np.ones(p)), ord='fro')
def convex_solver_cvxpy(
loss_fn,
value_and_grad,
params,
optim_variable_set,
data,
):
data = np.squeeze(np.array(data))
p = data.shape[1]
dim = int(p * (p + 1) / 2)
s = len(optim_variable_set)
non_opt_mark_vec = np.ones(dim, dtype=bool)
non_opt_mark_vec[optim_variable_set] = False
non_opt_indices_mat = (
np.triu_indices(p)[0][non_opt_mark_vec],
np.triu_indices(p)[1][non_opt_mark_vec],
)
Omega = cp.Variable((p, p), PSD=True)
constraints = [
Omega[non_opt_indices_mat] == np.zeros(dim - s),
]
graphical_guassian_loss = cp.norm(data @ Omega - np.diag(np.ones(p)), "fro")
prob = cp.Problem(cp.Minimize(graphical_guassian_loss), constraints)
prob.solve()
return graphical_guassian_loss.value, Omega.value[np.triu_indices(p)]
Below, we demonstrate the application of the loss function mentioned earlier to handle the same example as given in the Sparse Gaussian Precision Matrix documentation. We consider setting the sample size to be \(n=150\) and the dimensionality to be \(p=30\).
5.2.2.1. Random Structure#
We consider a graph structure where each pair of points is connected with a fixed probability.
[3]:
n, p = 150, 30
prng = np.random.RandomState(1)
prec = make_sparse_spd_matrix(p, alpha=0.98, smallest_coef=0.3, largest_coef=0.5, random_state=prng)
cov = np.linalg.inv(prec)
d = np.sqrt(np.diag(cov))
cov /= d
cov /= d[:, np.newaxis]
prec *= d
prec *= d[:, np.newaxis]
X = prng.multivariate_normal(np.zeros(p), cov, size=n)
X -= X.mean(axis=0)
X /= X.std(axis=0)
# sample covariance and precision matrix
cov_sample = np.cov(X.T)
prec_sample = np.linalg.inv(cov_sample)
Next, we minimize the loss function using the ScopeSolver from the scope package to obtain an estimate of the sparse precision matrix, given the known size of the true support set.
[4]:
solver = ScopeSolver(
dimensionality=int(p * (p + 1) / 2),
sparsity=np.count_nonzero(prec[np.triu_indices(p)]),
preselect=np.where(np.triu_indices(p)[0] == np.triu_indices(p)[1])[0],
numeric_solver=convex_solver_cvxpy,
)
solver.solve(
graphical_loss,
cov_sample,
init_params=np.eye(p)[np.triu_indices(p)],
)
prec_ = np.zeros((p, p))
prec_[np.triu_indices(p)] = solver.params
prec_ = np.where(
prec_, prec_, prec_.T
)
Next, we calculate the accuracy of the scope estimator in selecting the support set.
[5]:
def estimate_accuracy(actual_matrix, estimated_matrix):
p = actual_matrix.shape[0]
return (np.sum((actual_matrix != 0) == (estimated_matrix != 0)) - p) / (p ** 2 - p)
print('Scope: ', estimate_accuracy(prec, prec_))
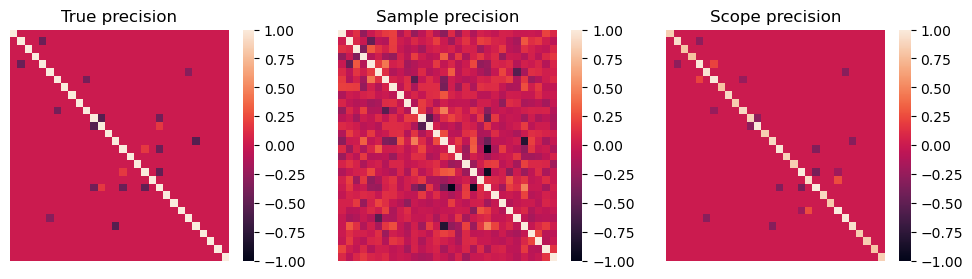
Scope: 0.9862068965517241
Below, we present the matrix heatmaps of the true precision matrix, the sample precision matrix, and the precision matrix estimated by scope.
[6]:
fig, axes = plt.subplots(1, 3, figsize=(12, 3))
sns.heatmap(prec, vmin=-1, vmax=1, ax=axes[0])
axes[0].set_xticks([])
axes[0].set_yticks([])
axes[0].set_title('True precision')
sns.heatmap(prec_sample, vmin=-1, vmax=1, ax=axes[1])
axes[1].set_xticks([])
axes[1].set_yticks([])
axes[1].set_title('Sample precision')
sns.heatmap(prec_, vmin=-1, vmax=1, ax=axes[2])
axes[2].set_xticks([])
axes[2].set_yticks([])
axes[2].set_title('Scope precision')
plt.show()
5.2.2.2. Band Structure#
We consider the graph structure corresponding to a random vector with some variables form a Markov chain. We follow the identical procedure mentioned above to construct and manipulate the sample. We define a function that generates a desired symmetric positive definite matrix as follow.
[7]:
def sparse_spd_matrix(p, s, model=0, u=10, v=1):
# Create a zero matrix
matrix = np.zeros((p, p))
# Set diagonal elements
np.fill_diagonal(matrix, 1)
if model == 0:
# Set elements at positions (i-1, i) and (i, i+1)
np.fill_diagonal(matrix[1:, :s], u)
np.fill_diagonal(matrix[:s, 1:], u)
elif model == 1:
# Set elements at positions (0, i) and (i, 0)
matrix[0, :s] = u
matrix[:s, 0] = u
# Calculate the minimum eigenvalue
eigenvalues = la.eigvalsh(matrix)
lambda_min = np.min(eigenvalues)
if lambda_min < 0:
# Adjust the matrix if the minimum eigenvalue is less than 0
adjustment = abs(lambda_min) + v
matrix += adjustment * np.eye(p)
matrix *= u
# Check if the matrix is positive definite using Cholesky decomposition
try:
cholesky = la.cholesky(matrix)
except la.LinAlgError:
raise ValueError("The generated matrix is not positive definite!")
return matrix
[8]:
n, p, s = 150, 30, 10
prec = sparse_spd_matrix(p, s, model = 0)
cov = np.linalg.inv(prec)
d = np.sqrt(np.diag(cov))
cov /= d
cov /= d[:, np.newaxis]
prec *= d
prec *= d[:, np.newaxis]
X = prng.multivariate_normal(np.zeros(p), cov, size=n)
X -= X.mean(axis=0)
X /= X.std(axis=0)
# sample covariance and precision matrix
cov_sample = np.cov(X.T)
prec_sample = np.linalg.inv(cov_sample)
[9]:
solver = GraspSolver(
dimensionality=int(p * (p + 1) / 2),
sparsity=np.count_nonzero(prec[np.triu_indices(p)]),
preselect=np.where(np.triu_indices(p)[0] == np.triu_indices(p)[1])[0],
numeric_solver=convex_solver_cvxpy,
)
solver.solve(
graphical_loss,
cov_sample,
init_params=np.eye(p)[np.triu_indices(p)],
)
prec_ = np.zeros((p, p))
prec_[np.triu_indices(p)] = solver.params
prec_ = np.where(
prec_, prec_, prec_.T
)
[10]:
print('Scope: ', estimate_accuracy(prec, prec_))
Scope: 1.0
[11]:
fig, axes = plt.subplots(1, 3, figsize=(12, 3))
sns.heatmap(prec, vmin=-2, vmax=2, ax=axes[0])
axes[0].set_xticks([])
axes[0].set_yticks([])
axes[0].set_title('True precision')
sns.heatmap(prec_sample, vmin=-2, vmax=2, ax=axes[1])
axes[1].set_xticks([])
axes[1].set_yticks([])
axes[1].set_title('Sample precision')
sns.heatmap(prec_, vmin=-2, vmax=2, ax=axes[2])
axes[2].set_xticks([])
axes[2].set_yticks([])
axes[2].set_title('Scope precision')
plt.show()

5.2.2.3. Hub Structure#
Next, we consider a graph structure that includes a hub node. We employ the identical approach as described earlier to construct and handle the sample.
[12]:
n, p, s = 150, 30, 10
prec = sparse_spd_matrix(p, s, model = 1, u=1)
cov = np.linalg.inv(prec)
d = np.sqrt(np.diag(cov))
cov /= d
cov /= d[:, np.newaxis]
prec *= d
prec *= d[:, np.newaxis]
X = prng.multivariate_normal(np.zeros(p), cov, size=n)
X -= X.mean(axis=0)
X /= X.std(axis=0)
# sample covariance and precision matrix
cov_sample = np.cov(X.T)
prec_sample = np.linalg.inv(cov_sample)
[13]:
solver = GraspSolver(
dimensionality=int(p * (p + 1) / 2),
sparsity=np.count_nonzero(prec[np.triu_indices(p)]),
preselect=np.where(np.triu_indices(p)[0] == np.triu_indices(p)[1])[0],
numeric_solver=convex_solver_cvxpy,
)
solver.solve(
graphical_loss,
cov_sample,
init_params=np.eye(p)[np.triu_indices(p)],
)
prec_ = np.zeros((p, p))
prec_[np.triu_indices(p)] = solver.params
prec_ = np.where(
prec_, prec_, prec_.T
)
[14]:
print('Scope: ', estimate_accuracy(prec, prec_))
Scope: 0.9954022988505747
[15]:
fig, axes = plt.subplots(1, 3, figsize=(12, 3))
sns.heatmap(prec, vmin=-1, vmax=1, ax=axes[0])
axes[0].set_xticks([])
axes[0].set_yticks([])
axes[0].set_title('True precision')
sns.heatmap(prec_sample, vmin=-1, vmax=1, ax=axes[1])
axes[1].set_xticks([])
axes[1].set_yticks([])
axes[1].set_title('Sample precision')
sns.heatmap(prec_, vmin=-1, vmax=1, ax=axes[2])
axes[2].set_xticks([])
axes[2].set_yticks([])
axes[2].set_title('Scope precision')
plt.show()

From the matrix heatmaps of the three scenarios mentioned above, it can be observed that the scope estimator exhibits fewer erroneously selected elements when applied to this loss function.
5.2.3. Reference#
[1] Cai, T., Liu, W., & Luo, X. (2011). A constrained ℓ 1 minimization approach to sparse precision matrix estimation. Journal of the American Statistical Association, 106(494), 594-607.