2.6. Multiple response non-negativity identity link Poisson model#
2.6.1. Introduction#
Poisson Regression involves regression models in which the response variable is in the form of counts. In the case that your covariates would act additively, identity link is better than log link. Next is an example.
Chromatography (GC/MS analysis): In chromatography (GC/MS analysis) one would often measure the superimposed signal of several approx Gaussian shaped peaks and this superimposed signal is measured with an electron multiplier, which means that the measured signal are ion counts and therefore Poisson distributed.
Since each of the peaks have by definition a positive height and act additively and the noise is Poisson, a nonnegative Poisson model with identity link would be appropriate here, and a log link Poisson model would be plain wrong. Based on the above elaboration, we implement the code for simulating data as followed coupled with a visualization of the signals.
[1]:
import numpy as np
import matplotlib.pyplot as plt
def simulate_spike_train(n=200, npeaks=20, channels=1, peakhrange=(1000, 10000), seed=123, Plot=True):
np.random.seed(seed)
x = np.arange(n)
# Ensure number of peaks does not exceed the number of points
npeaks = min(npeaks, n)
# Sample peak locations
u = np.random.choice(x, npeaks, replace=False)
u.sort()
# Generate peak heights logarithmically within the specified range
h = 10 ** np.random.uniform(np.log10(min(peakhrange)), np.log10(max(peakhrange)), (npeaks, channels))
# Initialize the true coefficient array
a = np.zeros((n, channels))
a[u, :] = h
# Gaussian peak shape function
def gauspeak(x, u, w, h=1):
return h * np.exp(-((x-u)**2) / (2 * w**2))
# Create a banded matrix with Gaussian shapes
W = 5 # width of the Gaussian
X = np.column_stack([gauspeak(x, ui, W, 1) for ui in x])
# Generate the noiseless simulated signal
y_nonoise = X @ a
# Add Poisson noise to the signal
y = np.random.poisson(y_nonoise)
# Plotting
if Plot and channels == 1:
plt.figure(figsize=(10, 5))
plt.plot(x, y, label="Noisy Signal", linestyle='-', marker='')
plt.stem(x, a, 'r', markerfmt='ro', label="True Peaks", basefmt="r-")
plt.title("simluated GC-MS data (red=true peaks)")
plt.xlabel("Time")
plt.ylabel("Signal")
plt.legend()
plt.show()
if Plot and channels > 1:
plt.figure(figsize=(10, 8))
plt.imshow(y.T**0.1, aspect='auto', interpolation='nearest')
plt.colorbar(label='Noisy Signal (Power 0.1)')
plt.xlabel('Time')
plt.ylabel('Channel')
plt.title('simluated GC-MS data (red=true peaks)')
true_peaks = np.nonzero(a.sum(axis=1))[0]
for peak in true_peaks:
plt.axvline(x=peak, color='red', label='True Peaks' if peak == true_peaks[0] else "")
return {'y': y, 'X': X, 'a': a, 'supp':u}
data = simulate_spike_train()

The mathematical equation for Poisson regression with identity link is
With \(n\) independent data of the explanatory variables \(x\) and the response variable \(y\), we can estimate \(\beta\) by minimizing the negative log-likelihood function under sparsity constraint:
However, since \(\log(x_i^T \beta)\) requires that \(x_i^T \beta\) be non-negative, this presents difficulties for optimization. One solution is to use a weighted non-negative least squares (weighted NNLS) loss function as an approximation.
2.6.2. Solve the problem#
Here is Python code for solving sparse poisson regression problem:
[2]:
from jax import numpy as jnp
def loss(params, data):
n, channels = data['y'].shape
return jnp.sum(jnp.square((data['y'] - data['X'] @ params.reshape(n, channels))) / (data['y'] + 0.1))
Here is an example of recovering 20 true peaks from a noisy signal. The true signal and estimated signals are visualized for illustrating the quality of the estimated signals.
[3]:
from skscope.layer import NonNegative
from skscope import ScopeSolver
n, npeaks, channels = 1000, 20, 1
data = simulate_spike_train(n, npeaks, channels, seed=123)
solver = ScopeSolver(
dimensionality=n*channels,
sparsity=npeaks,
)
solver.solve(
objective=lambda params: loss(params, data),
layers=[NonNegative(dimensionality = n*channels)],
jit=True,
)
# Plotting
plt.figure(figsize=(10, 5))
plt.plot(np.arange(n), data['y'], label="Noisy Signal", linestyle='-', marker='')
plt.stem(np.arange(n), solver.params, 'r', markerfmt='ro', label="Estimated Peaks", basefmt="r-")
plt.title("simluated GC-MS data (red=estimated peaks)")
plt.xlabel("Time")
plt.ylabel("Signal")
plt.legend()
plt.show()

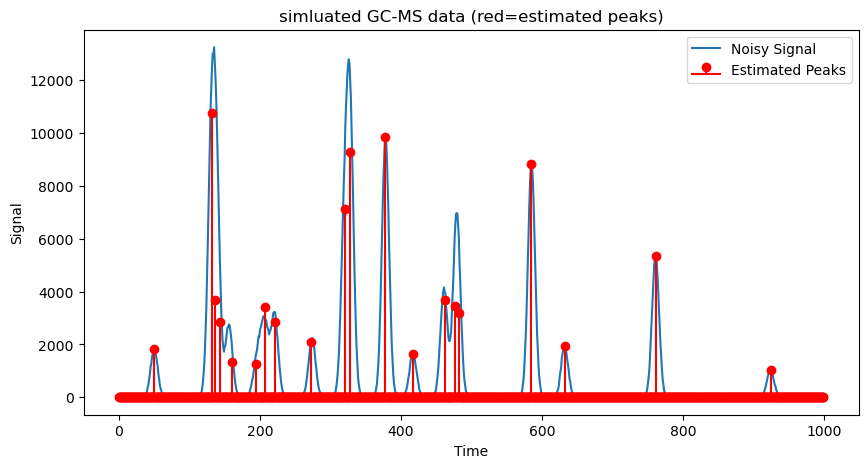
2.6.3. Case of multivariate#
In this part, we expand the dimension of the response to 50 to enrich the illustration of using skscope to solve sparsity-constraint optimization problem. Again, the true and estimated signals are both visualized.
[4]:
n, npeaks, channels = 1000, 10, 50
data = simulate_spike_train(n, npeaks, channels, seed=123)
solver = ScopeSolver(
dimensionality=n*channels,
sparsity=npeaks,
group=[i for i in range(n) for _ in range(channels)],
)
solver.solve(
objective=lambda params: loss(params, data),
layers=[NonNegative(dimensionality = n*channels)],
jit=True,
)
plt.figure(figsize=(10, 8))
plt.imshow(data['a'].T, aspect='auto', interpolation='nearest')
plt.colorbar(label='True Peaks')
plt.xlabel('Time')
plt.ylabel('Channel')
plt.title('True peaks and estimated peaks (red)')
true_peaks = np.nonzero(solver.params.reshape(n, channels).sum(axis=1))[0]
for peak in true_peaks:
plt.axvline(x=peak, color='red', label='Estimated Peaks' if peak == true_peaks[0] else "")

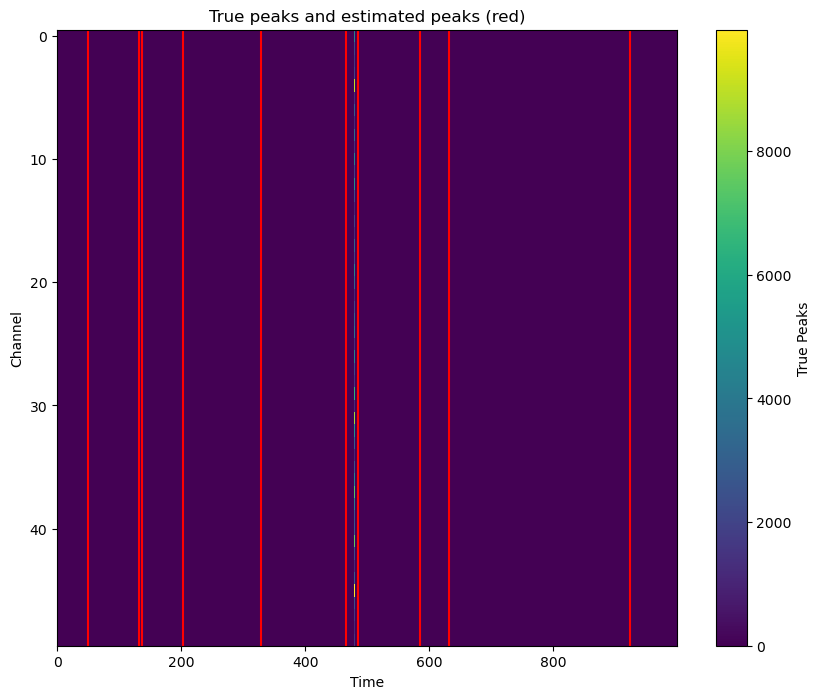
The covariate matrix can be coded as a sparse matrix to save memory, but solving it will be more time-consuming.
[5]:
from jax.experimental import sparse
n, npeaks, channels = 1000, 10, 50
data = simulate_spike_train(n, npeaks, channels, seed=123)
print(f"The size of dense covariate matrix is {data['X'].nbytes / (1024**2)} MB")
data['X'] = sparse.BCOO.fromdense(data['X'])
print(f"The size of sparse covariate matrix is {(data['X'].data.nbytes + data['X'].indices.nbytes) / (1024**2)} MB")
solver = ScopeSolver(
dimensionality=n*channels,
sparsity=npeaks,
sample_size=n,
group=[i for i in range(n) for _ in range(channels)],
)
solver.solve(
objective=lambda params: loss(params, data),
layers=[NonNegative(dimensionality = n*channels)],
jit=True,
)
plt.figure(figsize=(10, 8))
plt.imshow(data['a'].T, aspect='auto', interpolation='nearest')
plt.colorbar(label='Beta Value (Power 0.1)')
plt.xlabel('Time')
plt.ylabel('Channel')
plt.title('simluated GC-MS data (red=true peaks)')
true_peaks = np.nonzero(solver.params.reshape(n, channels).sum(axis=1))[0]
for peak in true_peaks:
plt.axvline(x=peak, color='red', label='True Peaks' if peak == true_peaks[0] else "")
The size of dense covariate matrix is 7.62939453125 MB
The size of sparse covariate matrix is 1.4714584350585938 MB

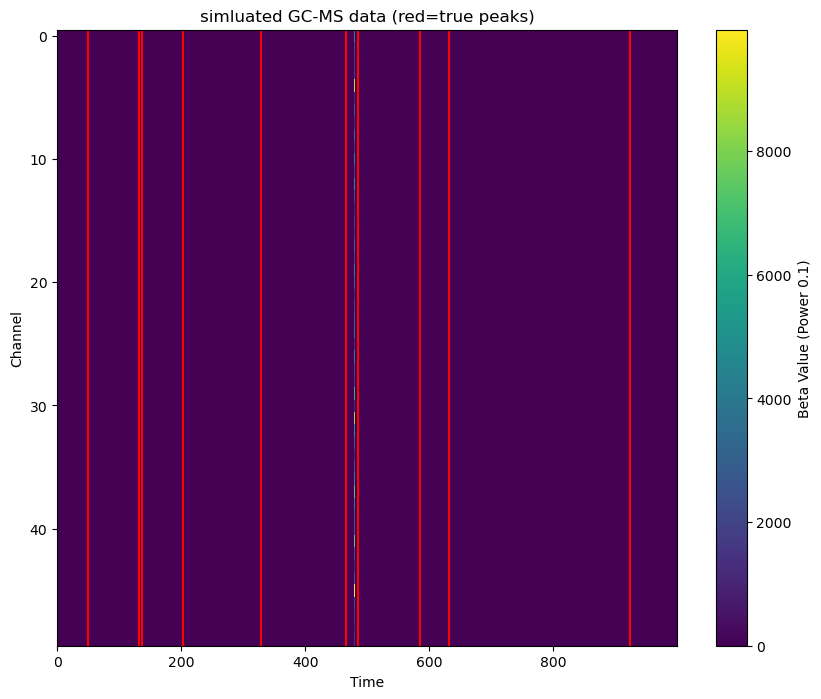
2.6.4. Case of large-scale dataset#
The last example shows the time consumption when the problem size is large in real situations.
[6]:
import time
from skscope import HTPSolver
n, npeaks, channels = 10000, 100, 500
data = simulate_spike_train(n, npeaks, channels, seed=123, Plot=False)
solver = HTPSolver(
dimensionality=n*channels,
sparsity=npeaks,
group=[i for i in range(n) for _ in range(channels)],
)
start_time = time.time()
solver.solve(
objective=lambda params: loss(params, data),
layers=[NonNegative(dimensionality = n*channels)],
jit=True,
)
print(f"Use {time.time() - start_time} s.")
plt.figure(figsize=(10, 8))
plt.imshow(data['a'].T, aspect='auto', interpolation='nearest')
plt.colorbar(label='Beta Value (Power 0.1)')
plt.xlabel('Time')
plt.ylabel('Channel')
plt.title('simluated GC-MS data (red=true peaks)')
true_peaks = np.nonzero(solver.params.reshape(n, channels).sum(axis=1))[0]
for peak in true_peaks:
plt.axvline(x=peak, color='red', label='True Peaks' if peak == true_peaks[0] else "")
Use 98.22258281707764 s.
